Lecture 3: Inverted File Index¶
倒排索引。
1 Structure¶
The real key technique used by search engines.
引入:举个栗子
假如我们想搜索带有“Computer Science”关键词的网站,有哪些方法?
- Solution 1: 对每个页面进行 "Computer Science" 字符串的扫描? Wait till your next life!!!
- Solution 2: 使用 Term-Document Incidence Matrix
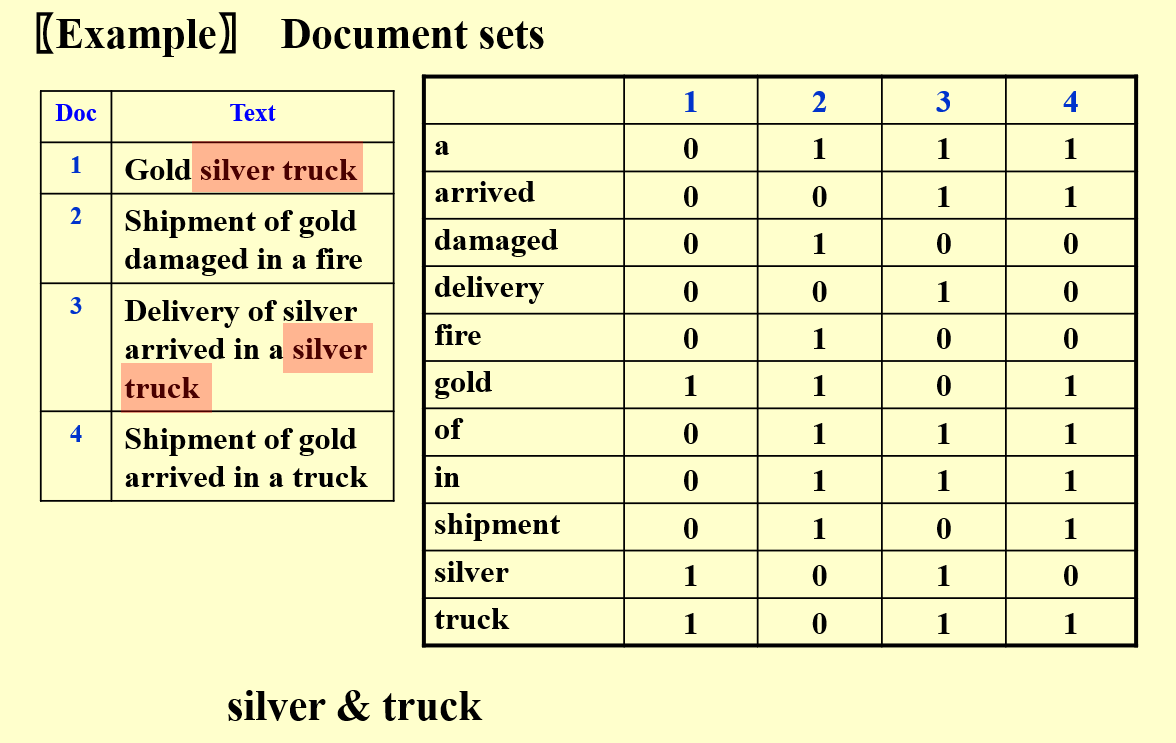
会出现的问题:矩阵可能会变得非常稀疏(有很多 0)。
如何解决?使用倒排索引。
定义
Index is a mechanism for locating a given term in a text. 简单来说就是一个存储位置的指针。
Inverted file contains a list of pointers (e.g. the number of a page) to all occurrences of that term in the text.
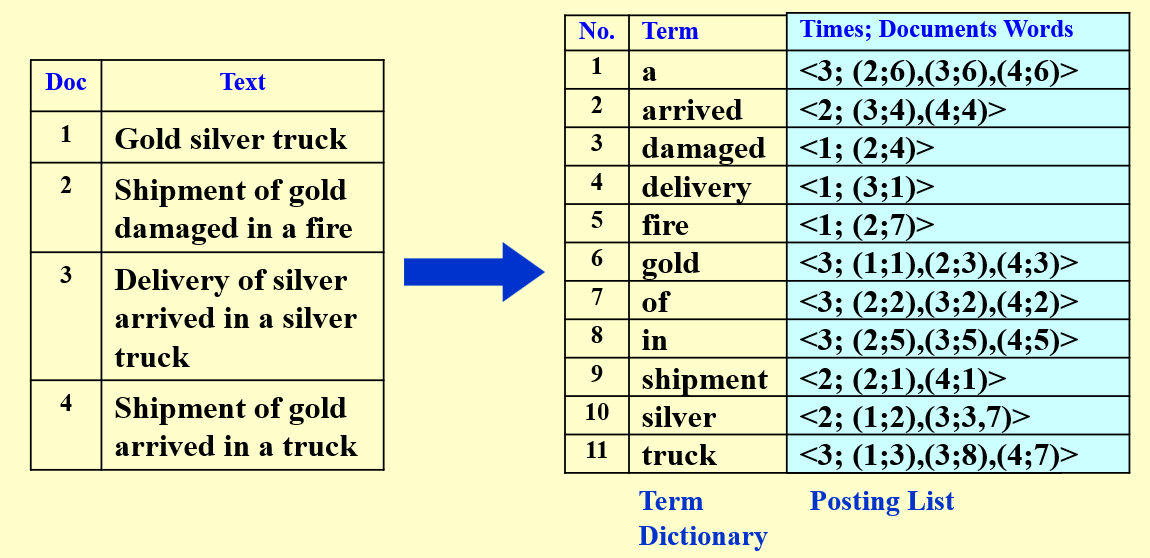
为什么要记录出现次数 Frequency
在做多关键词求交集结果的时候,我们常常选择从频率低的关键词入手,这样能够加快求解的速度。
问题变为如何生成这些 index。
Index Generator:
| Text Only | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
以上涉及很多部分,包括:
Token Analyzer, Stop Filter, Vocabulary Scanner, Vocabulary Insertor, Memory management 等等。
2 Modules¶
2.1 Word Stemming and Stop Filter¶
Word Stemming: 同样的词义,不同词性,只保留词根部分。
Stop Words: 某些太常见的词(a,is)等,不将其作为关键字。
2.2 Accessing the Terms¶
如何访问关键字呢?
Solution 1: 搜索树(B-树,B+树等等)
Solution 2: Hashing
哈希相对于搜索树的优缺点:
- 优点是访问单个关键词会更快(\(O(1)\))
- 缺点是访问连续的关键词序列通常做不到(range searches are expensive)
2.3 Memory Management¶
没有足够的内存?memory->hard disk.

3 Topics¶
3.1 Distributed Indexing¶
Each node contains index of a subset of collection.
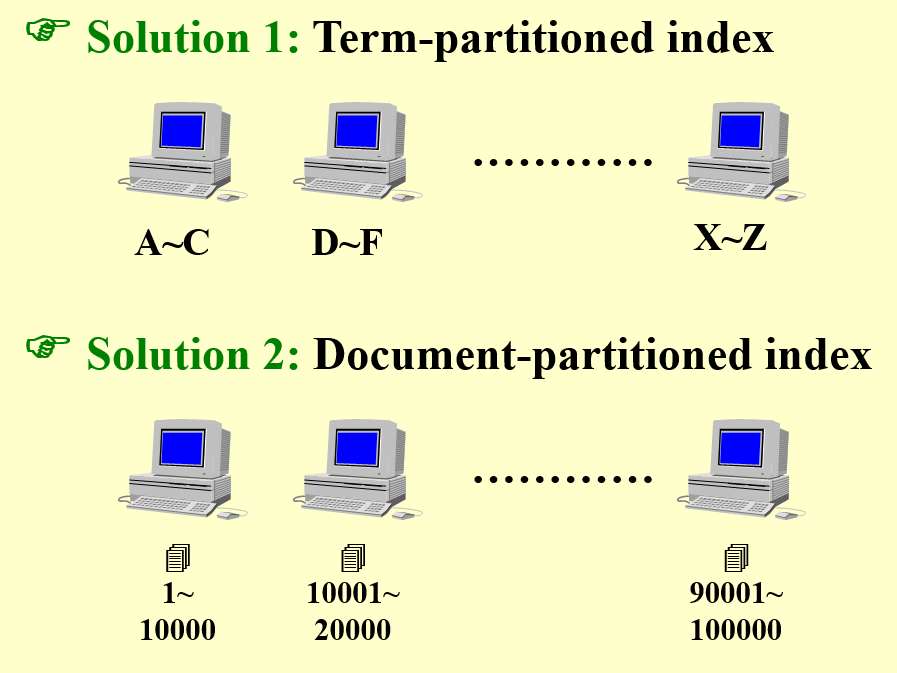
一般地我们采用上述两种方式的结合。
3.2 Dynamic Indexing¶
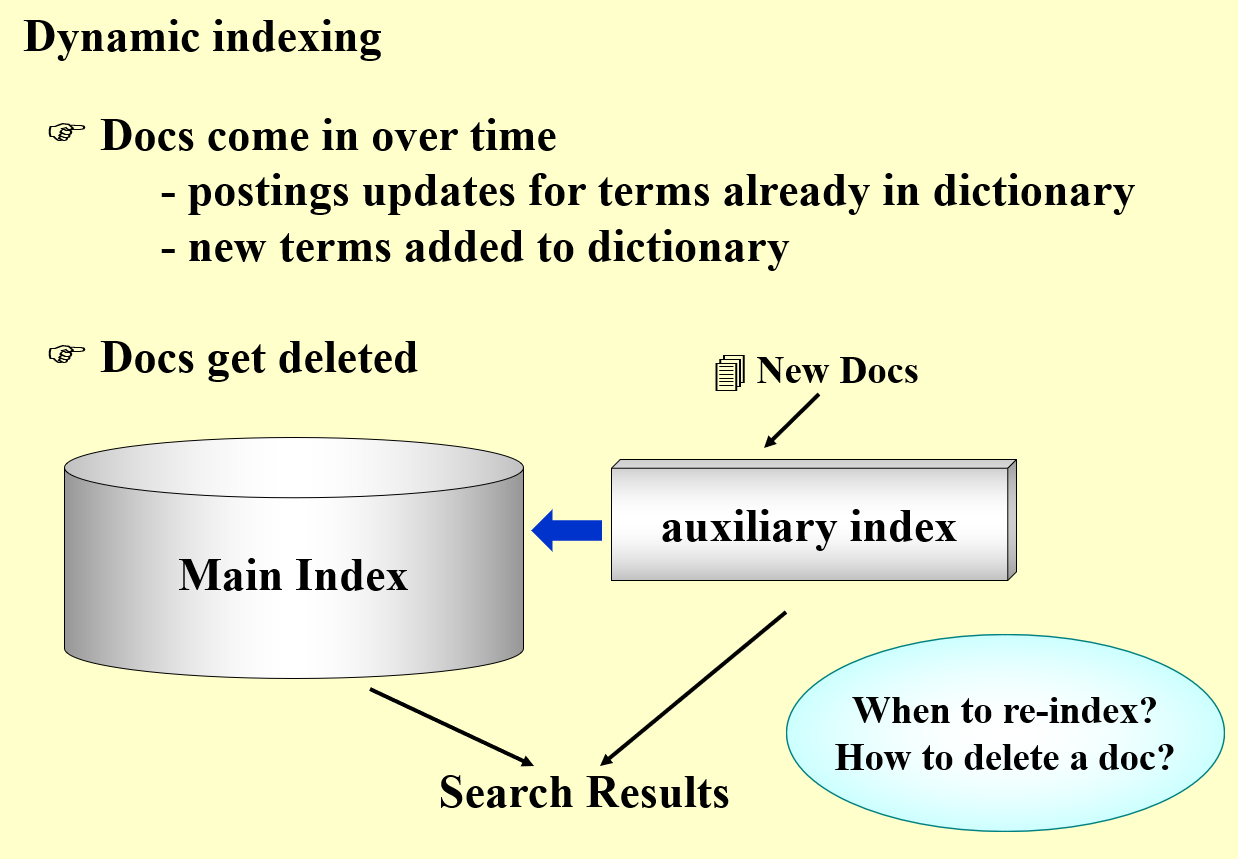
如图所示,一般采用一个主索引以及一个附加索引,新文档加入先归到附加索引中,需要访问的时候在两个索引中一起搜索关键词。需要注意两个问题:何时进行归并(re-index),以及如何删除文档。
3.3 Compression¶
存储许多数据,如何最大限度利用空间?

首先左上角是对关键词的压缩。先移除 Stop words, 然后将词会和在一起。然后再开一个空间存储不同单词之间的隔断信息。
右下角是对于 Posting List 的压缩,假设 computer 存在于第 2, 15, 47, ..., 58879, 58890 个文档中,我们记录每两个数字之间的差值,这样就能避免一些大数据的存储问题。
3.4 Thresholding¶
给某些操作设定阈值。
- Document: 对文档进行权重排序,只返回前 \(x\) 个结果;
缺点:对 Boolean 类型搜索(AND,OR等)不友好;可能由于截断而造成一些相关文档的缺失
- Query: 按照词频增序排列关键词;仅根据部分关键词的比例(阈值)进行搜索
Up to you.
4 Measures¶
4.1 Measure the Search Engines¶
如何衡量搜索引擎的好坏?
-
How fast does it index?
- Number of documents / hour
-
How fast does it search? -Latency as a function of index size
-
Expressiveness of query language
- Ability to express complex information needs
- Speed on complex queries
-
User happiness?
- Data Retrieval Performance Evaluation (after establishing correctness),侧重能搜索到的数据范围和速度
- Response time
- Index space
- Information Retrieval Performance Evaluation,侧重相关性
- How relevant is the answer set?
- Data Retrieval Performance Evaluation (after establishing correctness),侧重能搜索到的数据范围和速度
4.2 Measure the Relevancy¶
如何评估相关性?需要标准测试集以及评估标准。
- A benchmark document collection
- A benchmark suite of queries
- A binary assessment of either Relevant or Irrelevant for each query-doc pair.
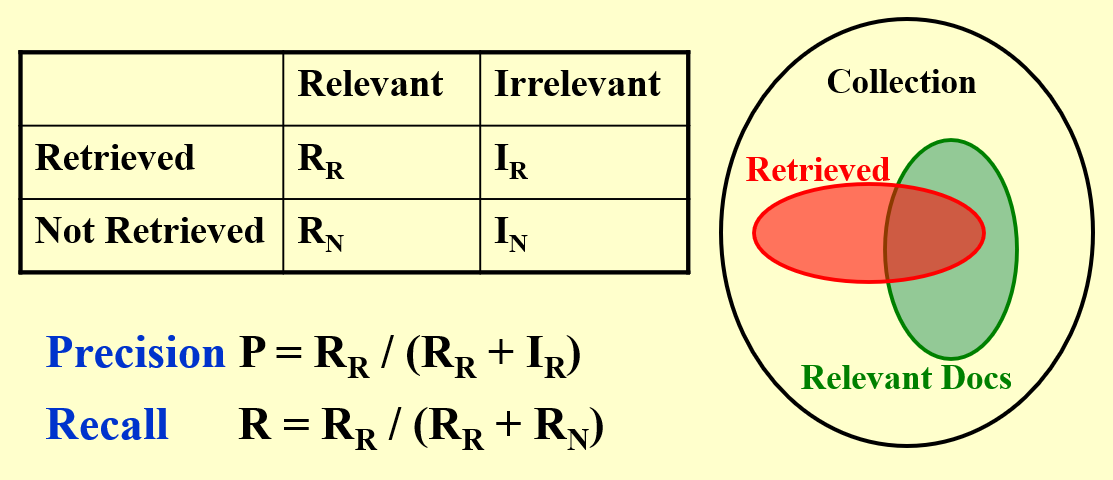
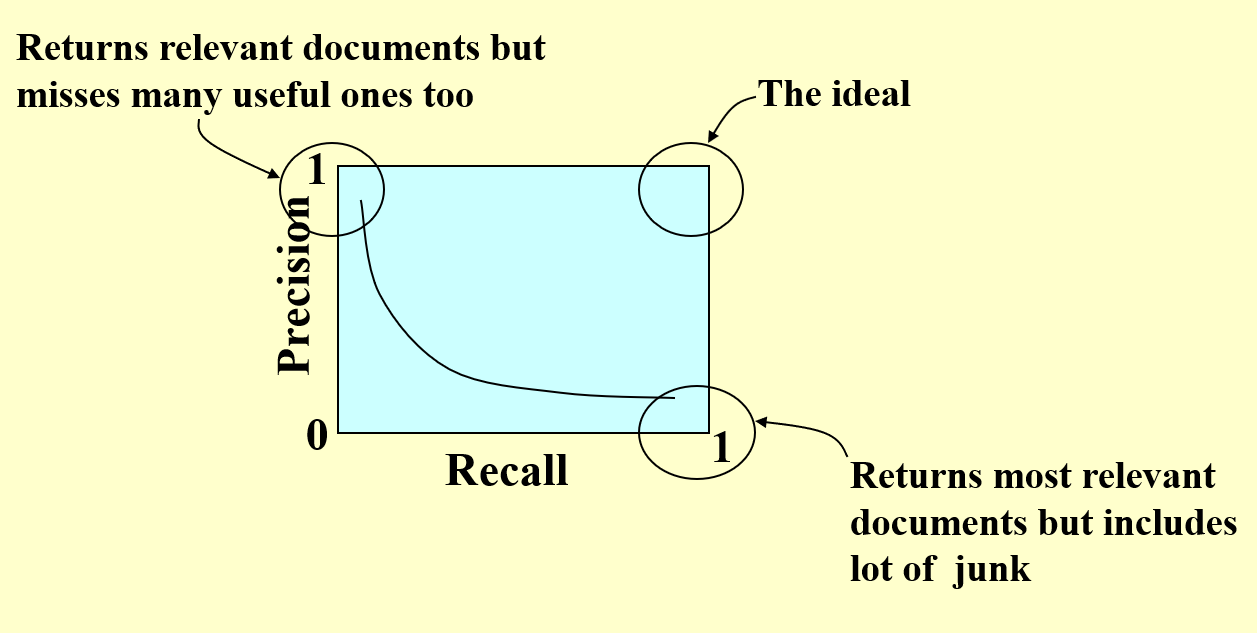
两个重要概念: Precision 和 Recall.
- Precision: 搜到的相关文档占搜索到的文档的比例。
- Recall: 搜到的相关文档占总的相关文档的比例。